 Don’t you hate when that email you were looking for ended up in your spam folder?
Don’t you hate when that email you were looking for ended up in your spam folder?
Or when you go through security at the airport and the medical detector flags your belt or shoes as something nefarious?
Or when you get a medical test back that indicated a problem only to find out everything was okay?
In these examples, a system is in place to detect a signal in the wash of noise: spam email, weaponry, or a disease. But in all cases what was detected was a false alarm, or what’s often called a false positive.
The concept of a false positive comes from signal detection theory. Correctly finding what to look for and raising the alarm is called a hit. Not raising the alarm and letting something pass is called a miss or a false negative. False negatives are a topic for a future article.
A visualization of what can go right and wrong in detection is shown in the figure below.
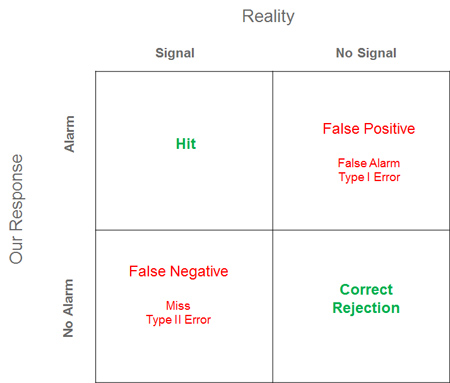
In the era of big data, we’re awash in a buzz of information, and much of it is noise. The trick is to separate the signal from the noise, which is more complicated than looking for the proverbial needle in a haystack. It’s more like looking for one type of needle in a stack of needles.
While it’s unlikely you’re in the business of catching bad guys sneaking contraband onto an airplane or detecting medical maladies, you’re still looking for evidence. Instead of contraband or maladies, it’s usability problems or evidence of a better design in the customer experience. In such cases, you need to watch out for false positives.
Two of the more common types of false positives encountered in UX research are phantom problems and illusory differences.
Phantom Problems
Phantom problems are problems identified using an evaluation method (for example, usability testing or Heuristic Evaluation) that turn out not to be problems. For example, identifying a label as confusing for users, when in fact the specialized user base is very familiar with the term, would be a phantom problem.
Inspection methods in particular have often been criticized for identifying problems that are potentially false positives. After all, when there’s no actual evidence that a user encounters a problem—only an expert’s opinion of a potential problem—is it really a problem?
The Comparative Usability Evaluations (CUE) made clear that different evaluators will uncover different problems—even when watching the same sets of users complete the same tasks. There’s already a limited amount of resources available to fix usability issues; if some of those resources are used to “fix” false positives, then it’s at best a wasted effort and at worse introduces new problems to users.
Medical tests, medical detectors, and spam filters all find phantom problems, which mean the innocent, healthy, and wanted mail get flagged as malicious.
But unlike spam filters and metal detectors where we can easily and objectively determine if a problem is legitimate, it can be difficult to know if a UX problem is a false positive. Both the time between identifying a problem and the symptoms of the problems can be difficult to measure.
When in doubt, triangulate to minimize phantom problems. Use complementary methods and redundant evaluators where possible. Data has consistently shown that multiple evaluators working independently are better judges of problems. Those evaluators are even more effective when they are “double-experts”—they have knowledge of both interaction principles and of the domain and end users.
Fortunately, even though different evaluators tend to uncover different issues, when the differences are examined, the evaluators agree there are actually issues even when they didn’t catch the problems. Supplementing an inspection method with a usability evaluation (if possible) also helps ensure the problems aren’t phantom (or perceived as phantom).
Illusory Differences
Comparing designs on key UX metrics is an excellent way to make data driven decisions about which design offers a superior experience. Even though numbers and statistics can determine the winner, they may not eliminate false positives. An illusory difference is when we declare a design, product, or whatever we’re comparing as better when in fact it’s not.
Just because we see statistical significance between designs doesn’t mean there actually is a difference. There probably is a difference, but there’s no guarantee there is one. For example, if you’re running an A/B test and get a p-value of .03 (in favor of design A), you’d most likely decide Design A is better than B and move forward with it. But a p-value of .03 tells us that we could expect to see a difference that large (if there really was no difference) about 3% of the time. The p-value tells us the probability of a false positive. It’s also called a Type I error (as shown in the figure above).
It’s often the case that the highest acceptable false positive rate is 5% (a p-value of less than .05). What that means is that for every 100 statistical comparisons we make, 5 of them will be false positives. These can be higher conversion rates, increased satisfaction, or shorter task times.
What’s even more troubling though is that most research efforts include many comparisons and questions: each of them increases the chances of a false positive. This turns our false positive rate of 5% into something much less palatable—like 20% or 50% (called alpha inflation)!
False positives can never be completely eliminated, but they can be reduced by managing the false positive rate and using replication. Techniques, like the Bonferroni correction and Benjamini–Hochberg procedure[pdf], reduce the false positive rate even if we make many comparisons. It’s a topic we discuss in our 2nd edition of Quantifying the User Experience.
Replicating studies in UX research also helps ensure that what you’ve found isn’t a statistical aberration. Replicating your findings should increase your confidence in your conclusions. False positives are a problem for the larger scientific community as well. A recent analysis found only around a third of published studies were able to be replicated!
Summary
False positives are a fact of life when trying to separate the signal from the noise in UX research. As the amount of data we use to make decisions increases, the reality of dealing with false positives does too. Two common types of false positives are phantom usability issues and illusory differences.
While we can never completely eliminate false positives, we can minimize them. In UX research this is best done by managing the false positive rate, replicating studies, and triangulating data with complementary methods and multiple evaluators.


