 Usability is attitude plus action.
Usability is attitude plus action.
Attitudes and actions are measured during a usability test where a representative sample of users are asked to complete tasks.
During the test we collect task-based metrics of performance (completion rates, task-time and errors) and perception (task-level difficulty).
We created the Single Usability Metric (SUM) to summarize these task metrics for company dashboards and to track improvements over time.
At the end of the test session we also administer a short survey of 10-20 items to gauge the user’s perceptions of the product. These surveys almost always include standardized questionnaires like the System Usability Scale (SUS) for software and applications, and the SUPR-Q for websites.
But there often isn’t enough time or it’s logistically difficult to conduct usability tests. This is especially the case if there are many products or websites with massive amounts of functionality.
What if you just had users answer the questionnaires outside of a usability test? Can you reliably infer what task performance would be from just having users answer the post-test questionnaires? I usually say no, but some recent data I analyzed made me think we might have some idea.
Performance and Attitudes
To help answer this question I looked to our survey of over 100 usability tests[pdf] from across a dozen organizations where we found that task performance and scores on standardized questionnaires, most of which were the SUS (80%), were modestly correlated. The correlation was usually between an r of .2 and .3. That means that the post-test questionnaire scores explain just 10%-15% of task success or failure.
That’s not terribly strong but it does tell us that task performance is tied loosely to the perception of the software or website usability when looking within the same usability test.
However, when I aggregated the data at a more macro level and rounded completion rates into 10 percentage point buckets, a stronger relationship emerged. For example, a task completion rate of 76% fell into the 80% bucket. In total I looked at 833 users’ task experiences with a product or website.
The graph below shows the correlation between each of the task completion rate buckets and SUS scores. SUS scores range from 0 to 100 with higher scores reflecting better usability. When looked at using this aggregated level we see a very strong correlation (r = .9). Put another way, SUS scores are explaining around 80% of the differences in aggregated task completion rates.
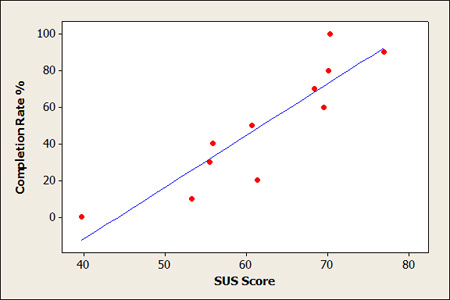
Figure 1: There is a strong positive correlation between completion rates rounded to the nearest 10% and SUS scores (r = .9). The regression equation is Comp = – 1.25 + 2.82 SUS (with SUS expressed as a percent out of 100).
You can see that the correlation, while strong, is not perfect. For example, users who had SUS scores on average of 70 had an average task completion rate of 60%. But SUS scores of 70 were also associated with completion rates of 100%.
You can also see that the lowest average SUS scores bottomed out at 40, well above the lowest possible score of 0.
The graph below provides another perspective. It shows the average SUS score by the completion rate buckets, the sample size and the 90% confidence intervals.
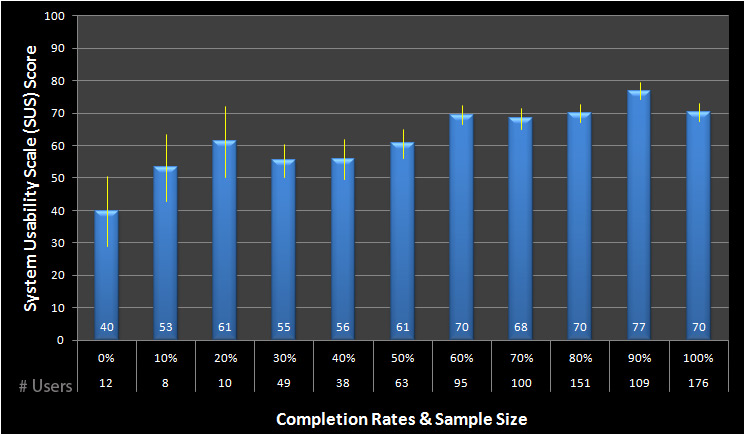
Figure 2: The mean SUS score for each completion rate bucket (0%-100%). The numbers represent the number of users and the yellow error bars are the 90% confidence intervals.
For example, there were 36 out of 833 users across the 122 studies that completed 40% of the tasks. Their average SUS scores was 56. The yellow error bars show the 90% confidence intervals. There is more precision for the groups with higher sample sizes (e.g. 80% completion rates versus 20% completion rates).
We can also see that users with 100% task completion rates had SUS scores that were 75% higher than those in the 0% task completion rate group (70 vs 40).
The non overlap in the confidence intervals also show us that the dip in SUS scores for the 100% versus 90% completion rate groups are NOT due to sampling error. I suspect there’s a sort of ceiling effect with task completion rates for certain products. That is, many users will complete all the tasks but not necessarily think the experience was easy.
To help put that into perspective, two of the data points come from an enterprise expense reporting web-application. Twenty six users performed the same tasks on both web-apps. One product had a SUS score that was 57% higher (53 vs 82) than the other. But the difference in task completion rates was much more modest : 89% vs 97% respectively. That is, most users completed most of the tasks on both applications, but they thought the experience was vastly different.
In the cases of software or tasks that are done frequently, task completion rates become less of a meaningful measure as users must complete tasks (task failure= not getting reimbursed). But just because the task is completed doesn’t mean it was easy to use. And that’s the tepid relationship we see between SUS scores and completion rates for any given test.
The calculator below will convert a raw SUS score into an approximate completion rate using the regression equation derived from the data we analyzed. You can use other questionnaires by converting the raw score to a percent of the maximum possible score.


