Surveys are one of the most cost effective ways of collecting data from current or prospective users.
Surveys are one of the most cost effective ways of collecting data from current or prospective users.
Gathering meaningful insights starts with summarizing raw responses. How to summarize and interpret those responses aren’t always immediately obvious.
There are many approaches to summarizing and visually displaying quantitative data and it seems people always have a strong opinion on the “right” way.
Here are some of the most common survey questions and response options and some ways we’ve summarized them. We’ll cover many of these approaches at the Denver UX Bootcamp.
Binary Responses
If a question has only two possible response options (e.g., Male/Female, Yes/No, Agree/Disagree) then it is a binary (also called dichotomous) response option. Both options, when added, equal 100%. When summarizing just the sample of respondents, such as the percent of women who responded, you can use the ubiquitous pie graph.
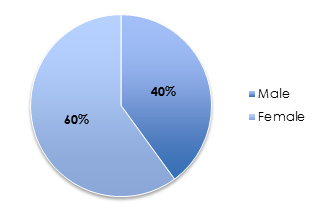
Or you could go with something a bit more USA Today:

However, when you want to estimate the percent of users in your entire user population (or at least out of those who are likely to participate in your survey) who would agree with a statement, then you’ll want to use confidence intervals around the percentage. The graph below shows the percentage of the 100 respondents that agreed to a statement.
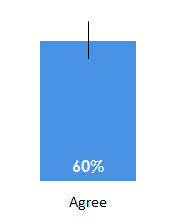
The black error bars show us how much we can expect this percentage to fluctuate, if we sample a higher number of participants, or even the entire population.
Rating Scales
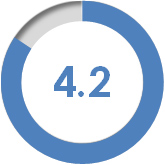
Rating scale questions can be those that explicitly ask participants to rate their level of agreement or satisfaction from 1 to 5, 1 to 7 or any bounded number range. You can also take questions that have ordered categories and assign numbers. For example, strongly disagree to strongly agree becomes 1 to 5.
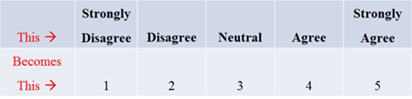
Then the average score for one item can become a 4.2 for example.
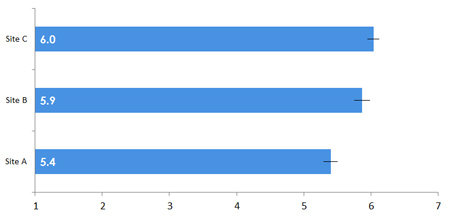
For making comparisons between questions (such as between different websites), find the mean, standard deviation and total number of responses for all questions and compute the confidence interval. Display them side-by-side along with error bars (shown below).
Single Select
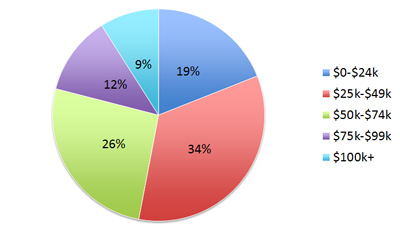
If participants are asked to pick one choice out of a number of alternatives, then this is a single-select response option. We summarize the proportion that chose each category. If you just want to summarize the responses in the survey, such as with income, a pie graph again will often suffice.
If, however, you want to estimate the prevalence of one response for the entire population (which is more common) to determine if it is statistically higher than another, then using bar graphs with confidence intervals will be more helpful.
For example, if respondents were asked the primary method by which they pay their online bill (laptop, smartphone, tablet or desktop), we can summarize this single-select question below.
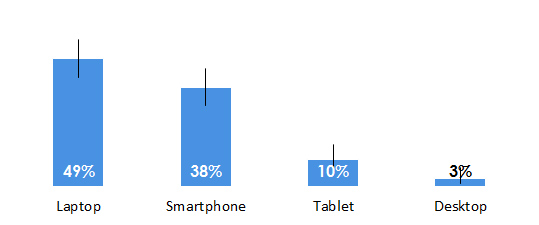
The total percentage selecting any category will add up to 100%. The percentages tell us the percent of respondents that selected the option, and the confidence intervals (black error bars) show us how much we could expect the percentages to fluctuate, if we were to sample all users (or even a much larger sample).
When error bars do not overlap, there is statistical significance. For example, even if thousands more participants responded to the survey in this example, it’s highly improbable that more participants pay their bill using a tablet versus using a smartphone.
Multiple Select
If participants are allowed to select “all that apply,” the total number of responses will add up to more than 100%. We can still summarize the proportion selecting using the binary confidence intervals used in the single-select method.
For example, the following graph shows the percent of respondents who selected each attribute they found important when looking for a computer to purchase.
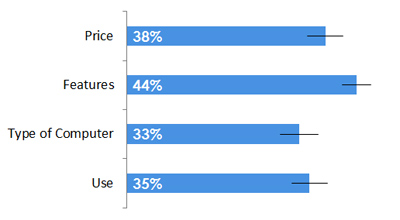
We can see that features were the most selected item, with 44% of the respondents selecting it. The confidence interval tells us that even if we had a much larger sample size, it’s extremely unlikely that features would become a less popular attribute than the others presented. The lower boundary of the error bar is still above the next choice (price).
Net Promoter Questions
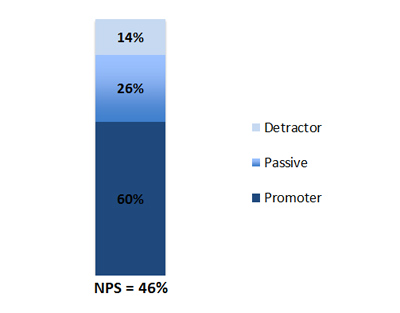
The Net Promoter Question (How likely is it that you’ll recommend a product to a friend?) is a rating scale, but is usually presented as a difference between two paired proportions–the proportion of promoters minus the proportion of detractors. An example NPS score of 46% is shown below.
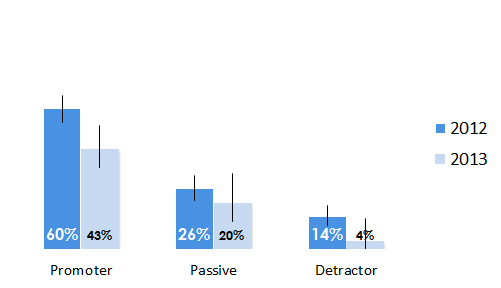
You can also compare the proportion of promoters, passives and neutrals separately to, say, an earlier year using confidence intervals again.
Forced Rank Questions
If you ask participants to rank options, such as the aspects they find the most important when purchasing a computer, it is a forced rank question. These look like rating scales but have different properties, called ipsative data, as each respondent’s score will add up to a fixed number (e.g. if there are six options to rank, each user’s responses will add up to 6+5+4+3+2+1 =21). Typically, you want to know which option has the statistically lowest rank (where lower numbers mean higher ranks) and we can also display the average rank with confidence intervals.
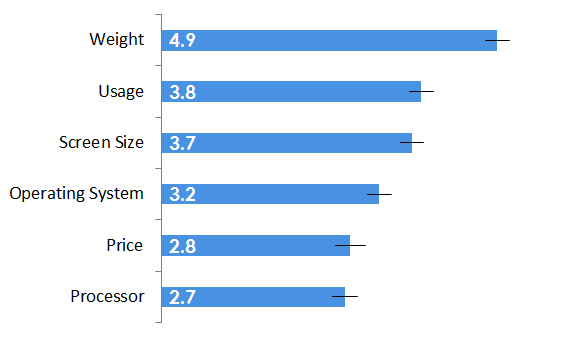
Processor in this case is the most important attribute, although not statistically distinguishable from price.
Open-Ended Comments
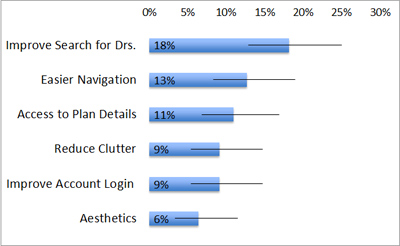
Most surveys will include at least one open-ended question. For example, what’s one thing would you improve on a website? While there are automatic ways of summarizing comments, such as matching algorithms or word clouds, we find taking the time to sort them with one or more analysts generates the best insights.
Once you have categories, you can then find the percentage of comments that fall into each group and even put confidence intervals around these. The graph below shows the most common categories derived from 110 participants’ open comments on what they would improve on their health provider’s website along with confidence intervals around the frequency.