 You can’t see customer satisfaction.
You can’t see customer satisfaction.
You can’t see usability.
There isn’t a thermometer that directly measures someone’s intelligence.
While we can talk about satisfied customers, usable products, or smart people, there isn’t a direct way to measure these abstract concepts.
And clearly these concepts vary. We’ve all had experiences that left us feeling unsatisfied or conversely very delighted. We’ve also had our share of products that were frustrating to use, and others which were surprisingly easy to use.
While we can’t measure these experiences directly, it’s these hidden and fluctuating concepts that we often need to measure and care about the most.
Variables
From an early age we become familiar with the concept of a variable. In Algebra we have equations such as:
2x = 4
In the equation, x is the variable.
In computer programming, a variable stores a value, just as it does in math. For example, the PHP variable $username stores the value of the username a person enters into a form:
$username = $_POST[‘username’];
In research, variables are things that change, and can be controlled and measured. For example, in an A/B test, if half the participants see a red button and half see a blue button on a donation page, the variable is the button color.
Independent vs Dependent Variables
More specifically, the button color is referred to as an independent variable, and is the one that is usually manipulated in a study. In contrast, the dependent variable is the number of clicks on the button (computed as a conversion rate).
Both the independent and dependent variables are observed variables. We can count the number of clicks, and as the researcher, see the difference in the button colors.
Observed vs Latent Variables
Many variables in UX research are observed. Things like responses to survey questions, standardized rating scales, time on task, task success, and usability problems are all observable (while usability itself isn’t observable).
But it’s often the variables we cannot see or directly measure that we want to know about, such as customer loyalty or usability. These hidden variables are referred to as latent (which is Latin for hidden). The Net Promoter Score (NPS) question and the 10 items in the System Usability Scale (SUS) measures observed variables (rating scales, time on task, and others) as a way to estimate the unobserved variables of customer loyalty and usability respectively.
How to Measure Latent Variables
While we can’t measure latent variables directly, we can measure them indirectly by using observed variables. It’s similar to the technique for finding planets orbiting distant stars. The exoplanets aren’t directly seen (they are far too dim) but they can be observed indirectly by both the gravitation wobble they have on their parent star and the small amount of light they block out of view as they pass between their star and our telescopes.
Similarly, to measure latent variables in research we use the observed variables and then mathematically infer the unseen variables. To do so we use advanced statistical techniques like factor analysis, latent class analysis (LCA), structural equation modeling (SEM), and Rasch analysis. These techniques rely on the inter-correlations between variables.
For example, we identified the latent variable of usability in our 2009 paper[pdf] using a type of factor analysis (PCA) by examining the observed variables of time (a measure of efficiency), completion rates (a measure of effectiveness), and self-reported questionnaire responses (a measure of satisfaction) to uncover the latent variable of usability.
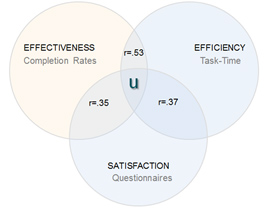
When we developed the SUPR-Q as a measure of the quality of the website user experience, we mapped observed items (8 items users respond to) to the latent constructs of UX variables, UX quality, appearance, usability, loyalty, and trust using structural equation modeling (SEM).

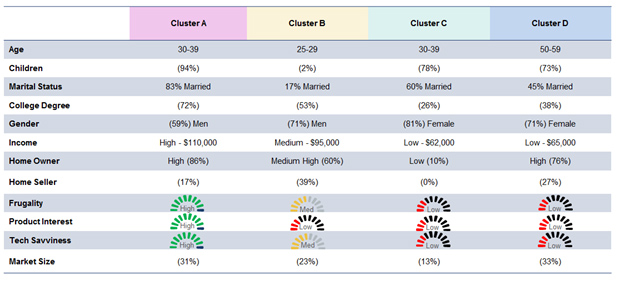
When we conduct a segmentation analysis we want to uncover unseen clusters of customers. We ask participants in a large survey to respond to many items. We take the observed responses and use latent class analysis to identify the underlying clusters.
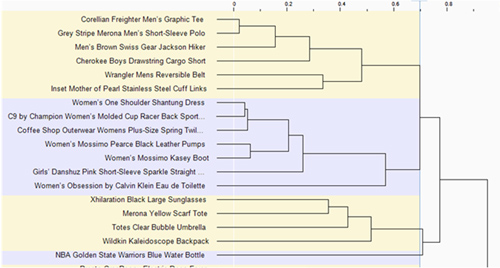
When we conduct a card sort to understand how users group information and items, we take the observed count of where participants place the items to infer the latent variable of groups.
Conclusion
Latent, or hidden, variables differ from observed variables in that they aren’t measured directly. Instead we use observed variables and mathematically infer the existence and relationship of latent variables. This is the core method behind many powerful techniques such as
- Factor analysis: To find underlying constructs
- Cluster analysis: To understand relationships using card sorting
- Latent class analysis: To group customers into segments
- Structural equation modeling (SEM): To validate measures


